
|
SHENGENG TANG 唐申庚
Lecturer at Hefei University of Technology, Ph.D. School of Computer Science and Information Engineering (SCSIE) Hefei University of Technology (HFUT) Email: tangsg@hfut.edu.cn Link: Teaching Homepage, Google Scholar, CSDN, ZHIHU, GitHub |
Biography
I earned my PhD degree (2022.12) from Hefei University of Technology (HFUT), under the supervision of Prof. Richang Hong (洪日昌). Before that, I received the B.E. degree from Hunan Normal University (HUNNU) in 2017. My research interests include multimedia computing and computer vision. Specifically, I focus on Sign Language Translation (SLT) and Sign Language Production (SLP).
If you are interested in visual understanding and cross-media learning, please visit our homepage of the Visual Understanding Team.
Researches
|
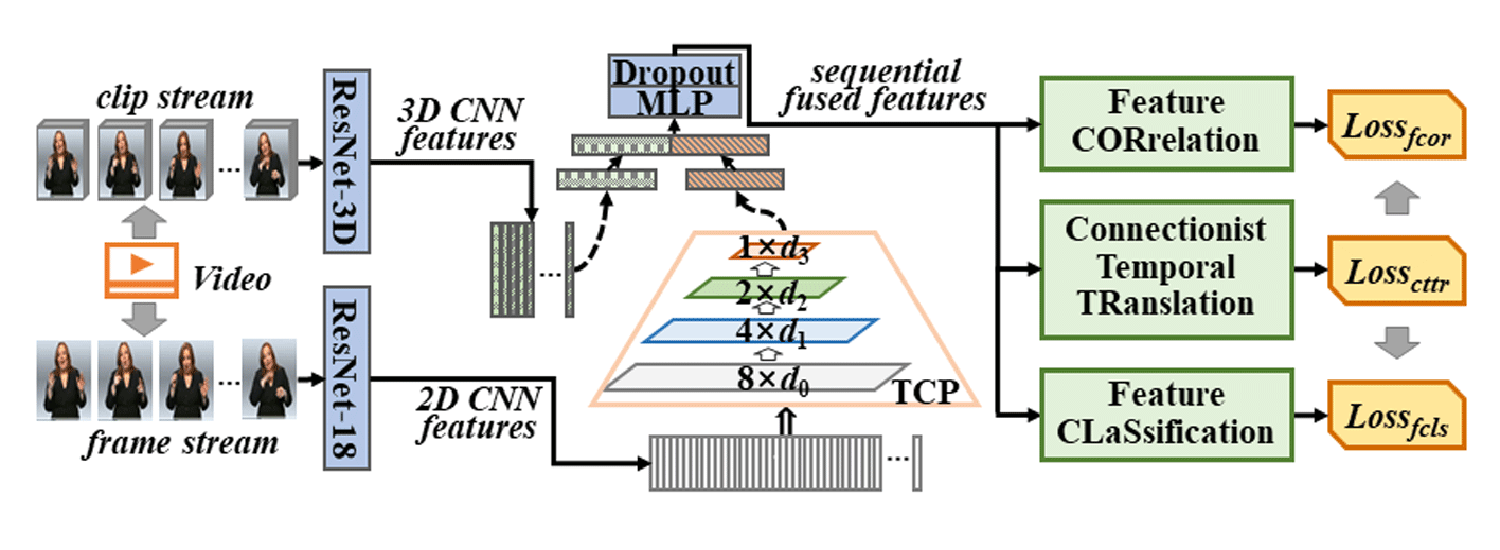
Connectionist Temporal Modeling of Video and Language: A Joint Model for Translation and Sign Labeling Dan Guo, Shengeng Tang, and Meng Wang International Joint Conference on Artificial Intelligence (IJCAI), 2019 [Link] [Paper] [BibTex] [Slides] [Poster] |
|
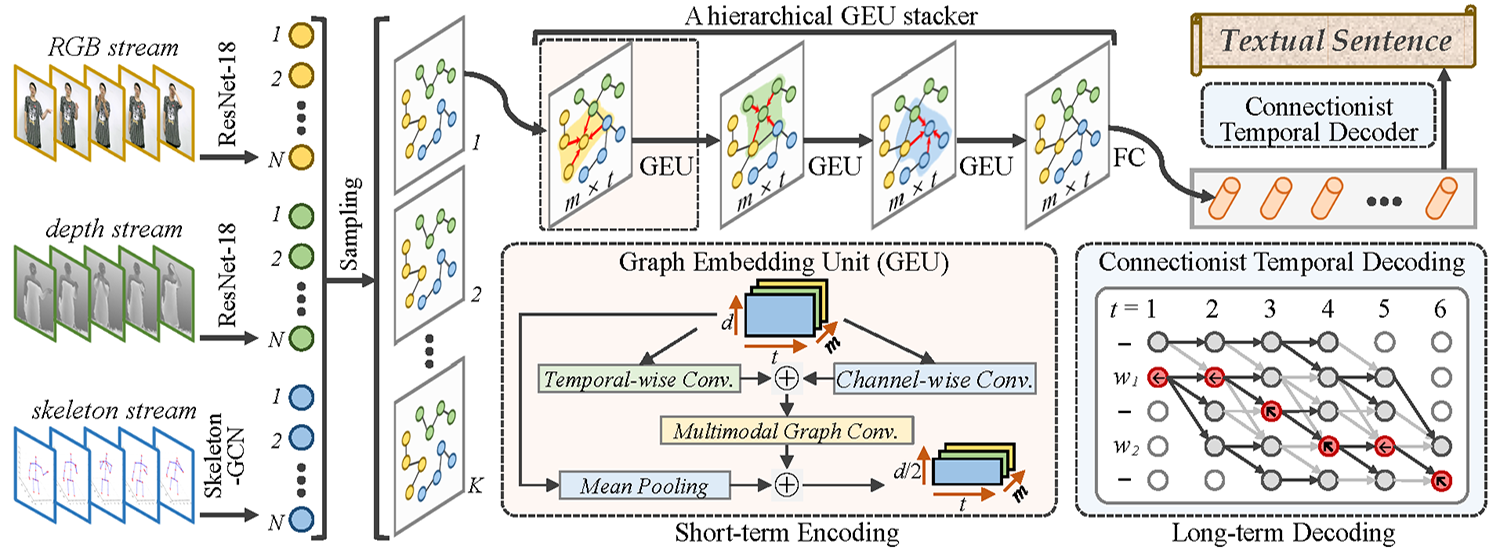
Graph-Based Multimodal Sequential Embedding for Sign Language Translation Shengeng Tang, Dan Guo, Richang Hong, and Meng Wang IEEE Transactions on Multimedia (TMM), 2022 [Link] [Paper] [BibTex] |
|
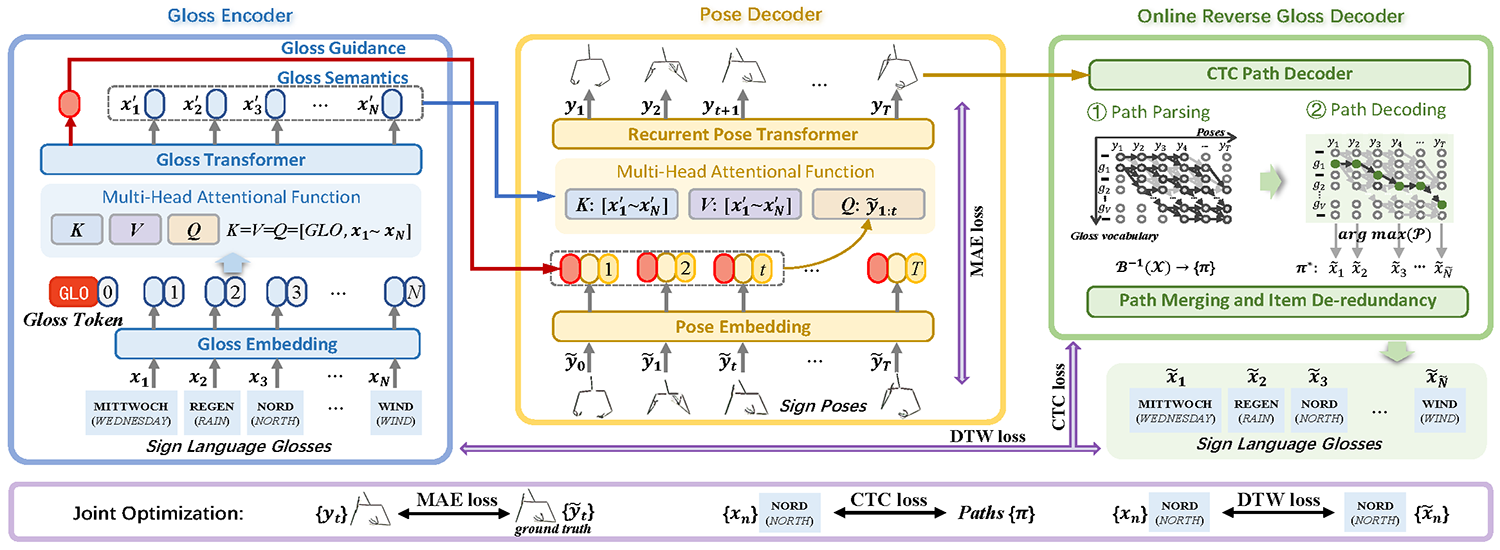
Gloss Semantic-Enhanced Network with Online Back-Translation for Sign Language Production Shengeng Tang, Richang Hong, Dan Guo, and Meng Wang ACM International Conference on Multimedia (ACM MM), 2022 [Link] [Paper] [BibTex] [Poster] [Video] |
|
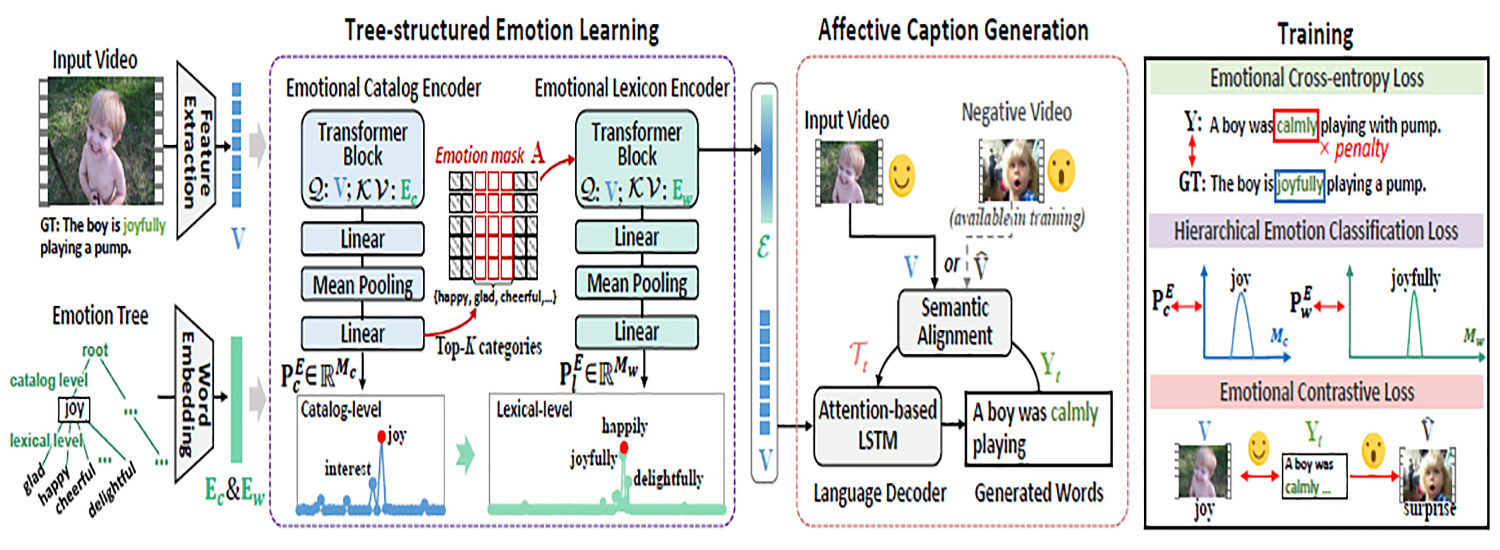
Emotion-Prior Awareness Network for Emotional Video Captioning Peipei Song, Dan Guo, Xun Yang, Shengeng Tang, Erkun Yang, and Meng Wang ACM International Conference on Multimedia (ACM MM), 2023 [Link] [Paper] [BibTex] |
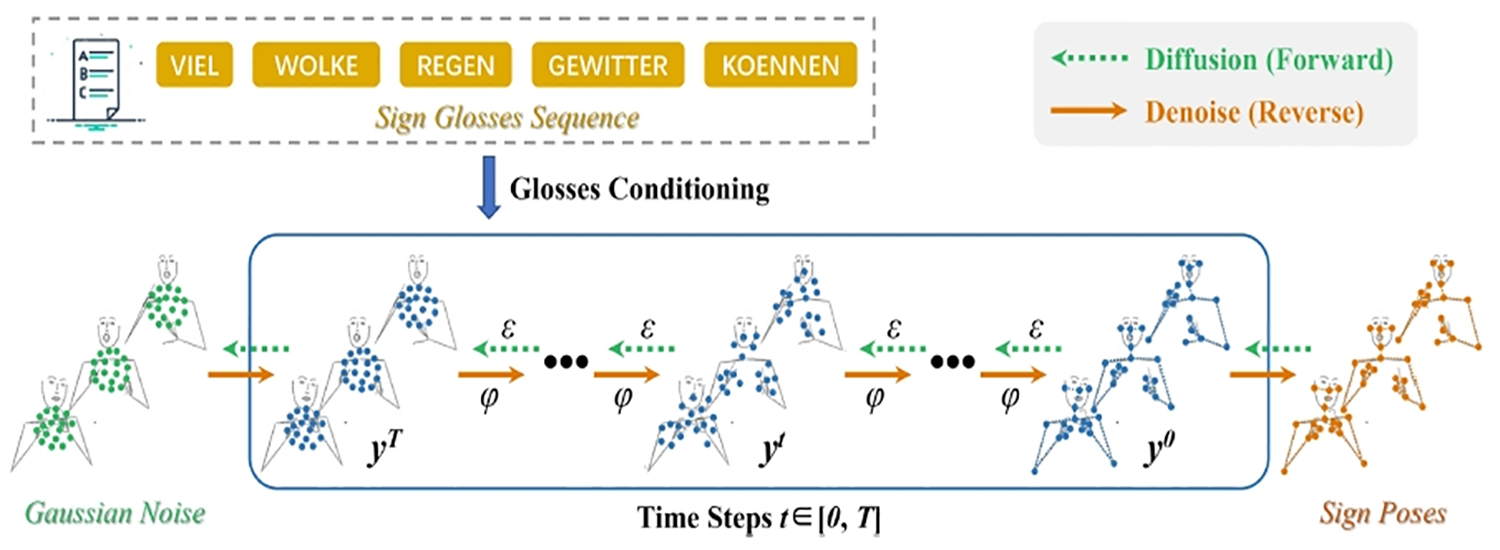
|
Gloss-driven Conditional Diffusion Models for Sign Language Production Shengeng Tang, Feng Xue, Jingjing Wu, Shuo Wang, and Richang Hong ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2024 [Link] [Paper] [BibTex] |
Publications
Conference papers:
- Shengeng Tang, Jiayi He, Lechao Cheng, Jingjing Wu, Dan Guo, Richang Hong. Discrete to Continuous: Generating Smooth Transition Poses from Sign Language Observations. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Shengeng Tang, Jiayi He, Dan Guo, Yanyan Wei, Feng Li, Richang Hong. Sign-IDD: Iconicity Disentangled Diffusion for Sign Language Production. AAAI Conference on Artificial Intelligence (AAAI), 2025, 39(7): 7266-7274.
- Dan Guo, Shengeng Tang, Meng Wang. Connectionist Temporal Modeling of Video and Language: a Joint Model for Translation and Sign Labeling. International Joint Conference on Artificial Intelligence (IJCAI), 2019: 751-757. [Link][PDF][BibTeX]
- Shengeng Tang, Richang Hong, Dan Guo, Meng Wang. Gloss Semantic-Enhanced Network with Online Back-Translation for Sign Language Production. ACM International Conference on Multimedia (ACM MM), 2022: 5630-5638. [Link][PDF][BibTeX]
- Peipei Song, Dan Guo, Xun Yang, Shengeng Tang, Erkun Yang, Meng Wang. Emotion-Prior Awareness Network for Emotional Video Captioning. ACM International Conference on Multimedia (ACM MM), 2023: 589-600. [Link][PDF][BibTeX]
- Jingjing Wu, Yunkai Zhang, Xi Zhou, Shengeng Tang*, Yanyan Wei*. Comprehensive Survey on Person Identification: Queries, Methods, and Datasets. International Conference on Multimedia Retrieval Workshop on Multimedia Object Re-Identification (ICMR-MORE), 2024: 1-6. [Link][PDF][BibTeX]
- Ziheng Zhou, Jinxing Zhou, Wei Qian, Shengeng Tang, Xiaojun Chang, Dan Guo. Dense Audio-Visual Event Localization under Cross-Modal Consistency and Multi-Temporal Granularity Collaboration. AAAI Conference on Artificial Intelligence (AAAI), 2025, 39(10): 10905-10913.
- Wei Qian, Gaoji Su, Dan Guo, Jinxing Zhou, Xiaobai Li, Bin Hu, Shengeng Tang, Meng Wang. PhysDiff: Physiology-based Dynamicity Disentangled Diffusion Model for Remote Physiological Measurement. AAAI Conference on Artificial Intelligence (AAAI), 2025, 39(6): 6568-6576.
- Zhangbin Li, Jinxing Zhou, Jing Zhang, Shengeng Tang, Kun Li, Dan Guo. Patch-level Sounding Object Tracking for Audio-Visual Question Answering. AAAI Conference on Artificial Intelligence (AAAI), 2025, 39(5): 5075-5083.
- Xu Wang, Shengeng Tang*, Peipei Song, Shuo Wang, Dan Guo, Richang Hong. Linguistics-Vision Monotonic Consistent Network for Sign Language Production. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.
- Kezhou Chen, Huixia Ben, Shuo Wang, Shengeng Tang, Yanbin Hao. Mixture of Multimodal Adapters for Sentiment Analysis. Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025.
- Jiaqi Zhao, Fei Wang, Kun Li, Yanyan Wei, Shengeng Tang, Shu Zhao, Xiao Sun. Temporal-Frequency State Space Duality: An Efficient Paradigm for Speech Emotion Recognition. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.
- Jiayi He, Shengeng Tang*, Ao Liu, Lechao Cheng, Jingjing Wu, Yanyan Wei. Efficient Vision Language Model Fine-tuning for Text-based Person Anomaly Search. ACM Web Conference Workshop on Multimedia Object Re-ID (WWW-MORE), 2025.
- Shuoyan Wei, Feng Li, Shengeng Tang, Yao Zhao, Huihui Bai. EvEnhancer: Empowering Effectiveness, Efficiency and Generalizability for Continuous Space-Time Video Super-Resolution with Events. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Mingce Guo, Jingxuan He, Yufei Yin, Zhangye Wang, Shengeng Tang, Lechao Cheng. Shaping a Stabilized Video by Mitigating Unintended Changes for Concept-Augmented Video Editing. International Joint Conference on Artificial Intelligence (IJCAI), 2025.
- Fangwen Wu, Lechao Cheng, Shengeng Tang, Xiaofeng Zhu, Chaowei Fang, Dingwen Zhang, Meng Wang. Navigating Semantic Drift in Task-Agnostic Class-Incremental Learning. International Conference on Machine Learning (ICML), 2025.
- Mingyu Xing, Lechao Cheng, Shengeng Tang, Yaxiong Wang, Zhun Zhong, Meng Wang. Knowledge Swapping via Learning and Unlearning. International Conference on Machine Learning (ICML), 2025.
Journal papers:
- Shengeng Tang, Dan Guo, Richang Hong, Meng Wang. Graph-Based Multimodal Sequential Embedding for Sign Language Translation. IEEE Transactions on Multimedia (TMM), 2022, 24: 4433-4445. [Link][PDF][BibTeX]
- Peipei Song, Dan Guo, Xun Yang, Shengeng Tang, Meng Wang. Emotional Video Captioning with Vision-based Emotion Interpretation Network. IEEE Transactions on Image Processing (TIP), 2024, 33: 1122-1135. [Link][PDF][BibTeX]
- Shengeng Tang, Feng Xue, Jingjing Wu, Shuo Wang, Richang Hong. Gloss-driven Conditional Diffusion Models for Sign Language Production. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2025, 21(4): 1-17. [Link][PDF][BibTeX]
- Zhenqiang Zhang, Kun Li, Shengeng Tang, Yanyan Wei, Fei Wang, Jinxing Zhou, Dan Guo. Temporal Boundary Awareness Network for Repetitive Action Counting. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2025, 21(4): 1-22.
- Jingjing Wu, Richang Hong, and Shengeng Tang. Intermediary-Generated Bridge Network for RGB-D Cross-modal Re-identification. ACM Transactions on Intelligent Systems and Technology (TIST), 2024, 15(6), 1-25. [Link][PDF][BibTeX]
- Chenglong Xu, Peipei Song, Shengeng Tang, Dan Guo, Xun Yang. Alleviating Confirmation Bias in Learning with Noisy Labels via Two-Network Collaboration. ACM Transactions on Intelligent Systems and Technology (TIST), 2025.
- 郭丹, 唐申庚, 洪日昌, 汪萌. 手语识别、翻译与生成综述. 计算机科学, 2021, 48(3): 60-70. [Link][PDF][BibTeX]
- 唐申庚, 修雪玉, 郭丹, 洪日昌. 基于智能生成技术的手语数字人发展现状与趋势. 人工智能, 2023, 4: 20-31. [Link][PDF][BibTeX]
Monographs:
- Dan Guo, Shengeng Tang, Richang Hong, and Meng Wang, "Sign Language Recognition", Multimedia for Accessible Human Computer Interfaces. Springer, Cham, 2021: 23-59. [Link][PDF][BibTeX]
Patents:
- 唐申庚; 王旭; 程乐超; 郭丹; 洪日昌; 基于跨模态语义关联学习的运动姿态生成方法, 2024-11-13, 中国, ZL202411612365.X. (授权)
- 唐申庚; 姚骏; 王旭; 修雪玉; 董晓虎; 谭惟尹; 郭丹; 一种基于多模态语义交互增强的手语生成系统及方法, 2024-11-12, 中国, ZL202410630950.6. (授权)
- 郭丹; 唐申庚; 刘祥龙; 洪日昌; 汪萌; 一种基于图卷积的多模态融合手语识别系统及方法, 2023-3-14, 中国, ZL202010049714.7. (授权)
- 郭丹; 唐申庚; 刘祥龙; 汪萌; 一种基于多层次语义解析的手语翻译系统及方法, 2023-3-28, 中国, ZL202010103960.6. (授权)
- 郭丹; 谷纪豪; 唐申庚; 肖同欢; 曹晨曦; 宋万强; 一种基于深度智能交互的室外视障辅助方法, 2024-2-20, 中国, ZL202210371804.7. (授权)
- 郭丹; 曹晨曦; 肖同欢; 唐申庚; 谷纪豪; 黄滨; 一种基于语义分割的择优式方向偏移预警系统和方法, 2024-2-27, 中国, ZL202210374860.6. (授权)
- 刁云峰; 姜凯超; 唐申庚; 郭丹; 汪萌; 一种针对人工智能合成图像的对抗鲁棒鉴伪方法, 2024-10-23, 中国, ZL202411482098.9. (授权)
- 唐申庚; 肖同欢; 郭丹; 谷纪豪; 曹晨曦; 宋万强; 黄滨; 一种基于图像目标检测和视觉深度估计的碰撞预警方法, 2023-2-27, 中国, CN202310188292.5. (实审)
- 唐申庚; 宋万强; 郭丹; 黄滨; 谷纪豪; 肖同欢; 曹晨曦; 一种基于带权无向图的视障人士路线规划方法, 2023-3-6, 中国, CN202310228006.3. (实审)
- 郭丹; 刘泽宽; 郭义臣; 唐申庚; 武梓龙; 文则涵; 陈颖男; 一种基于深度学习的WiFi手语翻译系统及方法, 2022-7-8, 中国, CN202210805408.0. (实审)
- 宋培培; 杨勋; 徐军军; 唐申庚; 王硕; 一种基于模态间互补性挖掘的多模态情感分析方法, 2024-4-12, 中国, CN202410442083.3. (实审)
- 杨勋; 徐成龙; 宋培培; 郝艳宾; 唐申庚; 一种基于双网络协作的抗噪音标签图像识别方法, 2024-8-16, 中国, CN202411126873.7. (实审)
Software copyright:
- 郭丹; 唐申庚; 陈颖男; 武梓龙; 文则涵; 刘泽宽; 基于关键点估计的人体姿态卡通化系统 V1.0, 2022SR0771364, 原始取得, 全部权利, 2022-06-16.
- 唐申庚; 黄滨; 郭丹; 谷纪豪; 盲人避障出行辅助系统 V1.0, 2023SR0517944, 原始取得, 全部权利, 2023-05-05.
- 唐申庚; 修雪玉; 郭丹; 董晓虎; 姚骏; 谢伟豪; 跨语言手语翻译系统 V1.0, 2023SR1107827, 原始取得, 全部权利, 2023-09-20.
- 唐申庚; 周家豪; 程乐超; 郭丹; 多源数据关联查询与推荐系统 V1.0, 2024SR1773469, 原始取得, 全部权利, 2024-11-13.
Experience
- 2023.02-Now, Lecturer, School of Computer Science and Information Engineering (SCSIE), Hefei University of Technology.
- 2017.06-2022.12, Ph.D, School of Computer Science and Information Engineering (SCSIE), Hefei University of Technology.
- 2013.09-2017.06, B.E, College of Information and Engineering (CISE), Hunan Normal University.
Professional Services
- Editorial Board Member for Medical Artificial Intelligence (MAI), Zentime
- Editorial Board Member for Eurasia Journal of Science and Technology (EJST), Upubscience
- PC Member/Reviewer for 37th/38th/39th AAAI Conference on Artificial Intelligence (AAAI 2023/2024/2025)
- TPC Member/Reviewer for 14th/15th/16th/17th International Conference on Creative Content Technologies (CONTENT 2022~2025)
- Reviewer for 36th/37th/38th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023/2024/2025)
- Reviewer for 19th/20th IEEE International Conference on Computer Vision (ICCV 2023/2025)
- Reviewer for 17th/18th European Conference on Computer Vision (ECCV 2022/2024)
- Reviewer for 13th International Conference on Learning Representations (ICLR 2025)
- Reviewer for 30th/31st/32nd/33rd ACM International Conference on Multimedia (MM 2022/2023/2024/2025)
- Reviewer for 40th ACM Conference on Human Factors in Computing Systems (CHI 2024)
- Reviewer for 50th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025)
- Reviewer for 17th IEEE International Conference on Multimedia & Expo (ICME 2025)
- Reviewer for 17th Asian Conference on Computer Vision (ACCV 2024)
- Reviewer for 19th Pacific Rim Conference on Multimedia (PCM 2018)
- Reviewer for IEEE Transactions on Multimedia (TMM), IEEE
- Reviewer for IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), IEEE
- Reviewer for ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), ACM
- Reviewer for Computer Vision and Image Understanding (CVIU), Elsevier
- Reviewer for Neural Networks, Elsevier
- Reviewer for Neurocomputing, Elsevier
- Reviewer for Soft Computing, Springer
- Reviewer for Multimedia Systems, Springer
- Reviewer for International Journal of Intelligent Systems, Wiley
Link
- Conferences Links: International Conferences on Machine Learning and Artificial Intelligence.
- CCF Conference DDLs: Information Update of International Conferences Recommended by CCF.